使用链接脚本指定程序内存布局
上一节中我们看到,编译出的程序默认被放到了从 0x10000 开始的位置上:
start address: 0x0000000000011000
...
Program Header:
PHDR off 0x0000000000000040 vaddr 0x0000000000010040 ...
LOAD off 0x0000000000000000 vaddr 0x0000000000010000 ...
LOAD off 0x0000000000001000 vaddr 0x0000000000011000 ...
STACK off 0x0000000000000000 vaddr 0x0000000000000000 ...
这是因为对于普通用户程序来说,数据是放在低地址空间上的。
但是对于OS内核,它一般都在高地址空间上。并且在 RISCV 中,内存(RAM)的物理地址也是从 0x80000000 开始的。因此接下来我们需要调整程序的内存布局,改变它的链接地址。
[info] 程序的内存布局
一般来说,一个程序按照功能不同会分为下面这些段:
- 段,即代码段,存放汇编代码;
- 段,即只读数据段,顾名思义里面存放只读数据,通常是程序中的常量;
- 段,存放被初始化的可读写数据,通常保存程序中的全局变量;
- 段,存放被初始化为 的可读写数据,与 段的不同之处在于我们知道它要被初始化为 ,因此在可执行文件中只需记录这个段的大小以及所在位置即可,而不用记录里面的数据。
- ,即栈,用来存储程序运行过程中的局部变量,以及负责函数调用时的各种机制。它从高地址向低地址增长;
- ,即堆,用来支持程序运行过程中内存的动态分配,比如说你要读进来一个字符串,在你写程序的时候你也不知道它的长度究竟为多少,于是你只能在运行过程中,知道了字符串的长度之后,再在堆中给这个字符串分配内存。
内存布局,也就是指这些段各自所放的位置。一种典型的内存布局如下:
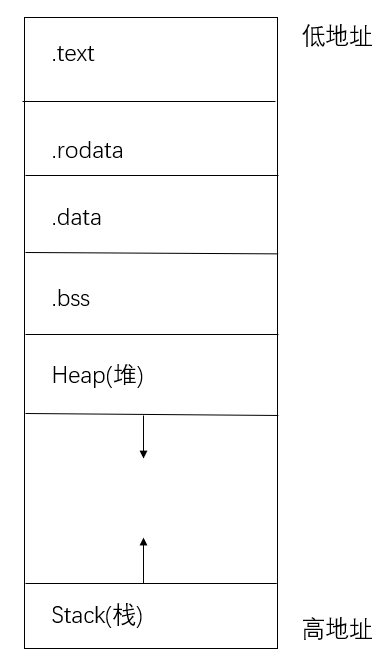
编写链接脚本
我们使用 链接脚本(linker script)来指定程序的内存布局。创建一个文件 src/boot/linker64.ld:
// src/boot/linker64.ld
OUTPUT_ARCH(riscv)
ENTRY(_start)
BASE_ADDRESS = 0x80200000;
SECTIONS
{
/* Load the kernel at this address: "." means the current address */
. = BASE_ADDRESS;
start = .;
.text : {
stext = .;
*(.text.entry)
*(.text .text.*)
. = ALIGN(4K);
etext = .;
}
.rodata : {
srodata = .;
*(.rodata .rodata.*)
. = ALIGN(4K);
erodata = .;
}
.data : {
sdata = .;
*(.data .data.*)
edata = .;
}
.stack : {
*(.bss.stack)
}
.bss : {
sbss = .;
*(.bss .bss.*)
ebss = .;
}
PROVIDE(end = .);
}
时至今日我们已经不太可能将所有代码都写在一个文件里面。在编译过程中,我们的编译器和链接器已经给每个文件都自动生成了一个内存布局。这里,我们的链接工具所要做的是最终将各个文件的内存布局装配起来生成整个程序的内存布局。
我们首先使用 OUTPUT_ARCH 指定了架构,随后使用 ENTRY_POINT 指定了入口点为 _start ,即程序第一条被执行的指令所在之处。在这个链接脚本中我们并未看到 _start ,回忆上一章,我们为了移除运行时环境依赖,重写了 C runtime 的入口 _start 。所以,链接脚本宣布整个程序会从那里开始运行。
链接脚本的整体写在 SECTION{ } 中,里面有多个形如 的语句,每个都描述了一个整个程序内存布局中的一个输出段 是由各个文件中的哪些输入段 组成的。
我们可以用 来表示将各个文件中所有符合括号内要求的输入段放在当前的位置。而括号内,你可以直接使用段的名字,也可以包含通配符 。
单独的一个 . 为当前地址 (Location Counter),可以对其赋值来从设置的地址继续向高地址放置各个段。如果不进行赋值的话,则默认各个段会紧挨着向高地址放置。将一个符号赋值为 . 则会记录下这个符号的地址。
到这里我们大概看懂了这个链接脚本在做些什么事情。首先是从 BASE_ADDRESS 即 0x80200000 (这确实是个高地址!) 开始向下放置各个段,依次是 。同时我们还记录下了每个段的开头和结尾地址,如 段的开头、结尾地址分别就是符号 的地址,我们接下来会用到。
这里面有两个输入段与其他长的不太一样,即 ,似乎编译器不会自动生成这样名字的段。事实上,它们是我们在后面自己定义的。
使用链接脚本
为了在编译时使用上面自定义的链接脚本,我们在 .cargo/config 文件中加入以下配置:
[target.riscv64imac-unknown-none-elf]
rustflags = [
"-C", "link-arg=-Tsrc/boot/linker64.ld",
]
它的作用是在链接时传入一个参数 -T 来指定使用哪个链接脚本。
我们重新编译一下,然后再次查看生成的可执行文件:
$ cargo build
...
Finished dev [unoptimized + debuginfo] target(s) in 0.23s
$ rust-objdump target/riscv64imac-unknown-none-elf/debug/os -h --arch-name=riscv64
target/riscv64imac-unknown-none-elf/debug/os: file format ELF64-riscv
Sections:
Idx Name Size VMA Type
0 00000000 0000000000000000
1 .text 00001000 0000000080200000 TEXT
2 .rodata 00000000 0000000080201000 TEXT
3 .data 00000000 0000000080201000 TEXT
4 .bss 00000000 0000000080201000 BSS
...
$ rust-objdump target/riscv64imac-unknown-none-elf/debug/os -d --arch-name=riscv64
target/riscv64imac-unknown-none-elf/debug/os: file format ELF64-riscv
Disassembly of section .text:
0000000080200000 stext:
80200000: 41 11 addi sp, sp, -16
80200002: 06 e4 sd ra, 8(sp)
80200004: 22 e0 sd s0, 0(sp)
80200006: 00 08 addi s0, sp, 16
80200008: 09 a0 j 2
8020000a: 01 a0 j 0
...
程序已经被正确地放在了指定的地址上。
到这里,我们清楚了最终程序的内存布局会长成什么样子。下一节我们来补充这个链接脚本中未定义的段,并完成编译。